数据结构05-字典-dict
大约 6 分钟
数据结构05-字典-dict
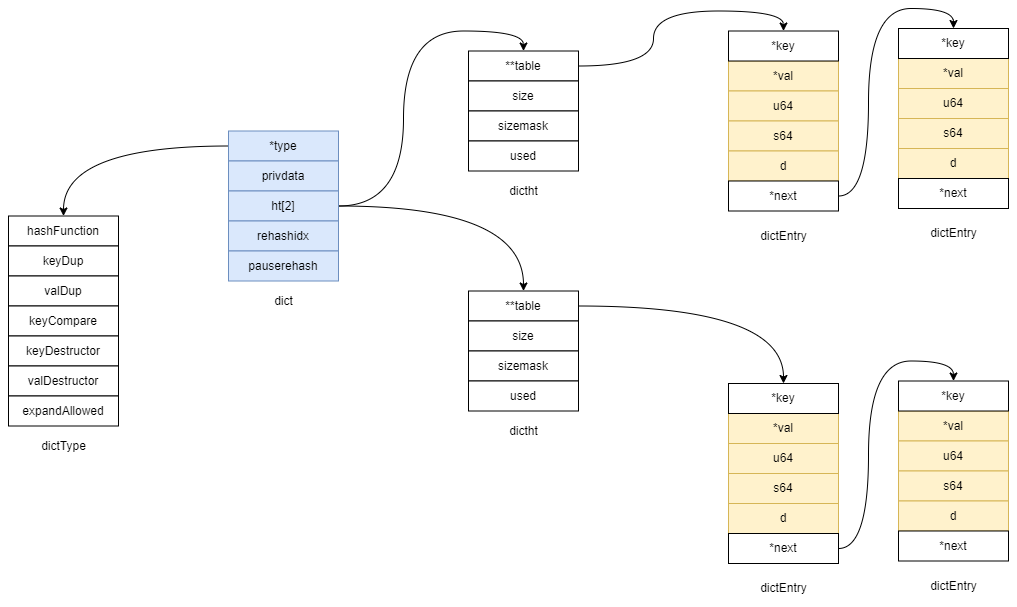
数据结构
/* 字典中的键值对实体 */
typedef struct dictEntry {
/* 键 */
void *key;
/* 值,共同体实现不同类型的存储 */
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
/* 下一个实体 */
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
/* 计算hash值的函数 */
uint64_t (*hashFunction)(const void *key);
/* 键复制函数 */
void *(*keyDup)(void *privdata, const void *key);
/* 值复制函数 */
void *(*valDup)(void *privdata, const void *obj);
/* 键对比函数 */
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
/* 键内存回收函数(析构函数) */
void (*keyDestructor)(void *privdata, void *key);
/* 值内存回收函数(析构函数) */
void (*valDestructor)(void *privdata, void *obj);
/* 判断是否可以扩容 */
int (*expandAllowed)(size_t moreMem, double usedRatio);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
/* 字典实体数组 */
dictEntry **table;
/* table的大小 */
unsigned long size;
/* 恒等于size - 1 */
unsigned long sizemask;
/* table中元素数量 */
unsigned long used;
} dictht;
/* 字典的结构体 */
typedef struct dict {
dictType *type; /* 字典类型,封装了各种函数,多态实现 */
void *privdata; /* 可以理解成是扩展字段 */
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 rehash的进度,当不是-1的时候,表示迁移至哪个table entry的下标 */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) 大于0表示rehash已停止,小于0表示出错,等于0表示正在迁移 */
} dict;
redis的字典类似于java的hashmap,在我看来,redis的实现比hashmap简单很多。
实现细节
多态
redis通过定义dictType结构体实现对hash函数、键复制函数、值复制函数、对比函数、键销毁函数、值销毁函数、是否允许扩展函数自定义。可以随意组合不同的算法。
初始化
- rehashidx:rehash的进度,当不是-1的时候,表示数组下标
- pauserehash:大于0表示rehash已停止,小于0表示出错,等于0表示正在迁移。在执行 BGSAVE 或 BGREWRITEAOF的时候,会把该值+1,表示暂停rehash
/* Create a new hash table */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
/* 分配内存 */
dict *d = zmalloc(sizeof(*d));
/* 初始化hash表 */
_dictInit(d,type,privDataPtr);
return d;
}
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
/* 初始化hash表1,置零 */
_dictReset(&d->ht[0]);
/* 初始化hash表2,置零 */
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->pauserehash = 0;
return DICT_OK;
}
新增数据
- 如果是rehash状态,会迁移一个bucket(数组中的一个链表)
- 如果是rehash状态,那么新插入的数据会在ht[1]中
- redis采用的是链地址法解决hash冲突
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
/* 判断是否在rehash状态,是的话执行迁移1个bucket */
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
/* 计算新插入元素的下标,如果key已经存在直接返回 */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
/* 判断字典是否在rehash,如果是的话,直接存进新的hash table中 */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
查找数据
- 如果是rehash状态,会迁移一个bucket(数组中的一个链表)
- 遍历两个hash table判断key是否相同,相同的话就返回
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict is empty */
/* 如果是在rehash,迁移一个bucket */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
/* 下面的步骤就是从两个hash table中找出key的value */
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
删除数据
- 如果是rehash状态,会迁移一个bucket(数组中的一个链表)
- 遍历删除
/* Search and remove an element. This is an helper function for
* dictDelete() and dictUnlink(), please check the top comment
* of those functions. */
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}
扩容策略(时机)
必须满足以下所有条件才会执行扩容
- 字典的元素总数量 大于 数组的长度
- 允许扩容(这里是一个字段控制的,redis的子进程在持久化的时候,也就是执行BGSAVE 或 BGREWRITEAOF的时候,会不允许扩容),或者当表中的元素总数量除于表的数组大小 > 5的时候
- 自定义的判断是否允许扩容函数expandAllowed返回true,如果没有定义,默认返回true
渐进式rehash
redis为了不要在rehash的时候做大量的数据迁移,设计了两个hash table。正常情况下,使用ht[0],当需要扩容的时候会把ht[1]分配内存到扩容后的长度,在新增、查找、删除、替换等操作的时候会迁移一个数组中的bucket(桶),新插入的数据也直接插入到ht[1]中。等全部迁移完后把ht[1]移动到ht[0],旧的ht[0]将释放内存。
子进程持久化
在执行BGSAVE、BGREWRITEAOF的时候,redis会fork一个子进程出来对redis的数据做持久化操作,那么持久化的动作与字典的操作就不是单线程了,为了最大化地利用系统的 copy on write 机制, 程序会暂时将 dict_can_resize 设为false(设置不允许扩容), 避免执行rehash ,从而减少父子进程的数据复制。因为不是单线程的原因,在执行后台持久化操作的时候,新插入的数据可能不会被持久化。