数据结构01-普通链表
大约 5 分钟
数据结构01-普通链表
基础知识
链表是比较常用的一个数据结构,在JAVA中的实现是LinkedList,但是在C的标准库中并没有内置的链表可供使用,所以redis实现了一套。我们知道数组的内存地址是连续的,最大的特征是支持随机访问,所以数组的读时间复杂度是O(1),但是在写的场景时间复杂度是O(N),在某个位置插入一条数据,需要把这个位置后的所有数据向后移动一位,在内存不足时还需要重新申请内存。
而链表的内存结构是不连续的,不支持随机访问,当需要读取某个位置的数据时,需要从头遍历到尾部才能实现,所有读是O(N);对链表写入操作时,因为两个节点的内存都是独立不连续的,在这中间插入数据的时候,只要把next、prev指针重新指向即可,所以写是O(1)。这就是数组和链表的基础知识,我们看下在redis中的具体实现是怎么样的吧!
普通链表
redis中链表实现
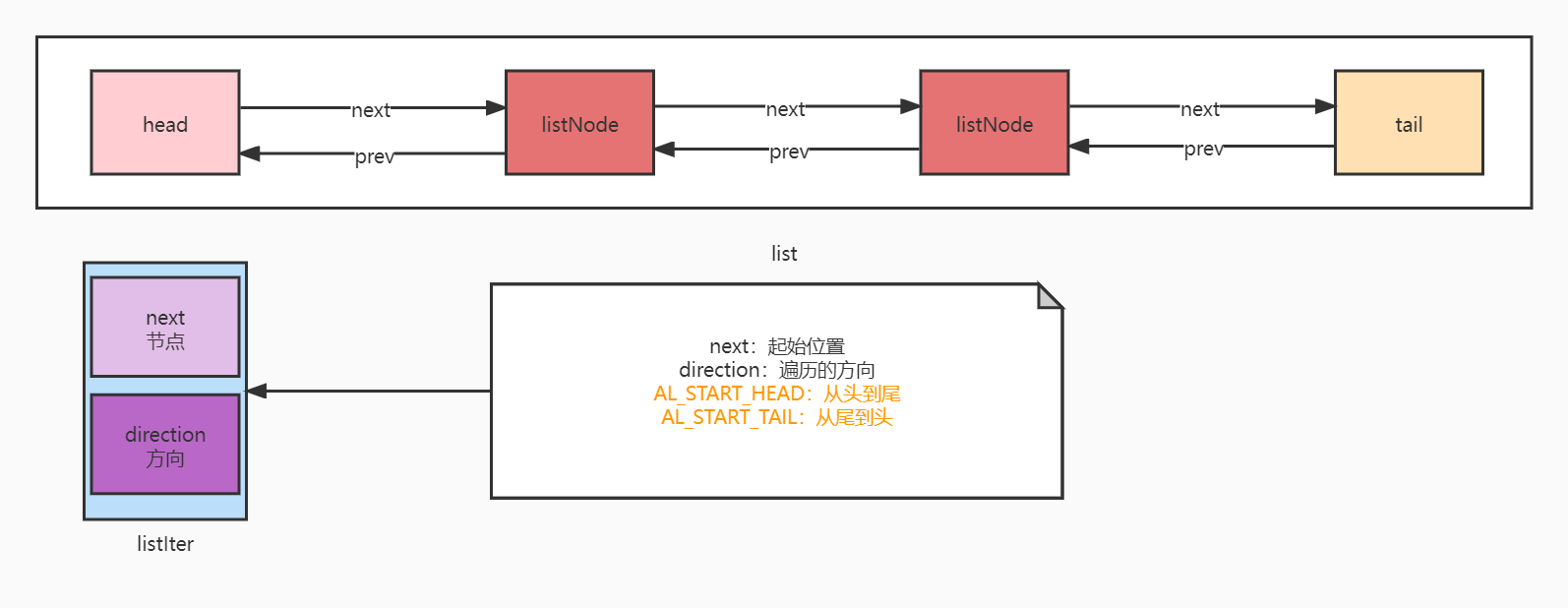
在redis源码中链表有三个关键的结构体,list、listNode、listIter,具体如下:
/* 链表中的节点,双端链表节点 */
typedef struct listNode {
/* 指向前一个节点 */
struct listNode *prev;
/* 指向下一个节点 */
struct listNode *next;
/* 节点的值 */
void *value;
} listNode;
/* 迭代器 */
typedef struct listIter {
listNode *next;
int direction;
} listIter;
/* 链表 */
typedef struct list {
/* 链表的头节点 */
listNode *head;
/* 链表的尾节点 */
listNode *tail;
/* 节点值复制函数 */
void *(*dup)(void *ptr);
/* 节点值释放函数 */
void (*free)(void *ptr);
/* 节点值对比函数 */
int (*match)(void *ptr, void *key);
/* 链表长度 */
unsigned long len;
} list;
把三个结构体的关系图如下:
创建链表
list *listCreate(void)
{
/* 定义链表的结构体 */
struct list *list;
/* 分配空间 */
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL;
/* 把头部和尾部初始化为NULL */
list->head = list->tail = NULL;
/* 长度 */
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}
清空链表
void listEmpty(list *list)
{
unsigned long len;
listNode *current, *next;
current = list->head;
len = list->len;
/* 遍历链表 */
while(len--) {
/* 获取下一个节点 */
next = current->next;
/* 如果当前节点的释放函数不是空的话,调用释放函数对节点的值进行释放 */
if (list->free) list->free(current->value);
/* 释放当前节点 */
zfree(current);
/* 把下一个节点复制给当前节点,下一次遍历使用 */
current = next;
}
/* 把头部和尾部清空 */
list->head = list->tail = NULL;
/* 把长度赋值为0 */
list->len = 0;
}
头部插入
/* 在链表头部插入,O(1) */
list *listAddNodeHead(list *list, void *value)
{
/* 创建一个节点 */
listNode *node;
/* 给创建的节点分配内存 */
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
/* 把值放到节点里面去 */
node->value = value;
/* 如果链表的长度是0的话 */
if (list->len == 0) {
/* 链表的头部和尾部的指针都指向这个节点 */
list->head = list->tail = node;
/* 节点的下一个节点和上一个节点都是NULL */
node->prev = node->next = NULL;
} else {
/* 因为是在头部插入,所以prev节点是NULL */
node->prev = NULL;
/* 把节点的下一个节点指向链表的头部节点 */
node->next = list->head;
/* 把原头部节点的上一个节点指向新创建的这个节点 */
list->head->prev = node;
/* 把链表的头部节点换成新创建的这个节点 */
list->head = node;
}
/* 链表长度+1 */
list->len++;
return list;
}
尾部插入
/* 在链表尾部插入 O(1) */
list *listAddNodeTail(list *list, void *value)
{
/* 创建一个节点 */
listNode *node;
/* 给创建的节点分配内存 */
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
/* 把值放到节点里面去 */
node->value = value;
/* 如果链表的长度是0的话 */
if (list->len == 0) {
/* 链表的头部和尾部的指针都指向这个节点 */
list->head = list->tail = node;
/* 节点的下一个节点和上一个节点都是NULL */
node->prev = node->next = NULL;
} else {
/* 新建节点的上一个节点指向链表的原尾部节点 */
node->prev = list->tail;
/* 因为是尾部插入,所以节点的下一个节点是空 */
node->next = NULL;
/* 把链表的原尾部节点的下一个节点指向新创建的这个节点 */
list->tail->next = node;
/* 把链表的尾部节点指向新建的这个节点 */
list->tail = node;
}
/* 链表长度+1 */
list->len++;
return list;
}
链表查找
/* 查找 */
listNode *listSearchKey(list *list, void *key)
{
/* 链表迭代器 */
listIter iter;
/* 节点 */
listNode *node;
/* 创建迭代器 */
listRewind(list, &iter);
/* 遍历链表 */
while((node = listNext(&iter)) != NULL) {
/* 如果链表有设置对比函数,则使用对比函数对比 */
if (list->match) {
if (list->match(node->value, key)) {
return node;
}
} else {
/* 判断返回 */
if (key == node->value) {
return node;
}
}
}
return NULL;
}
使用建议
从源码中得知链表的添加数据的速度是很快的,在不需要读取某个位置的值并且新增数据的操作比较多的情况下考虑使用链表数据结构。
快速链表
比链表更优的实现,后面补充