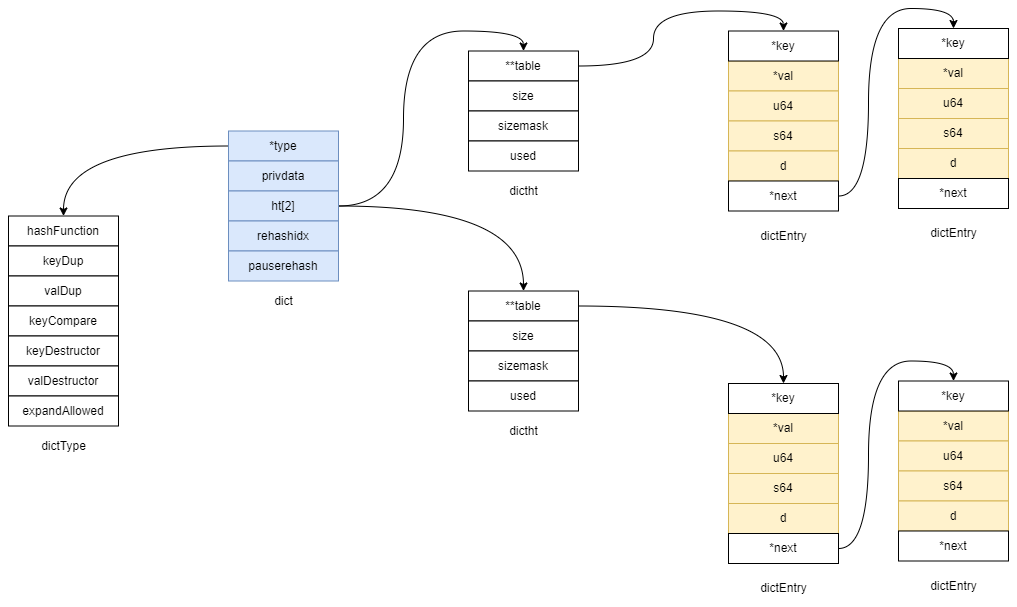
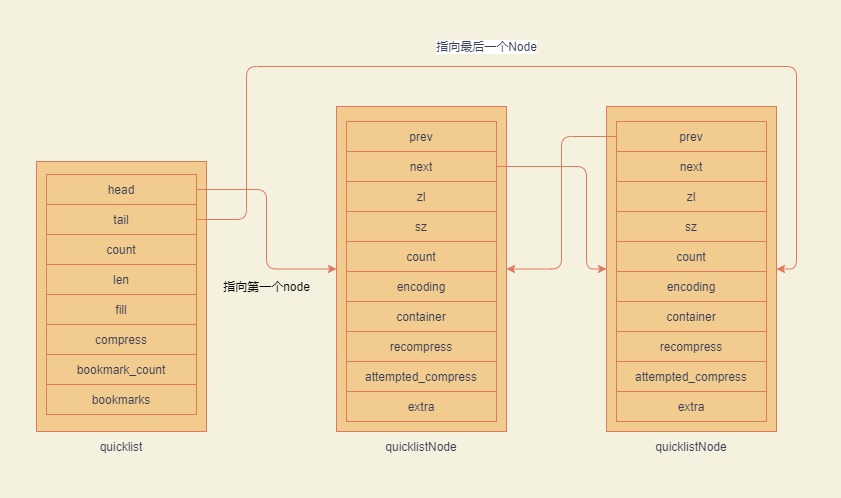
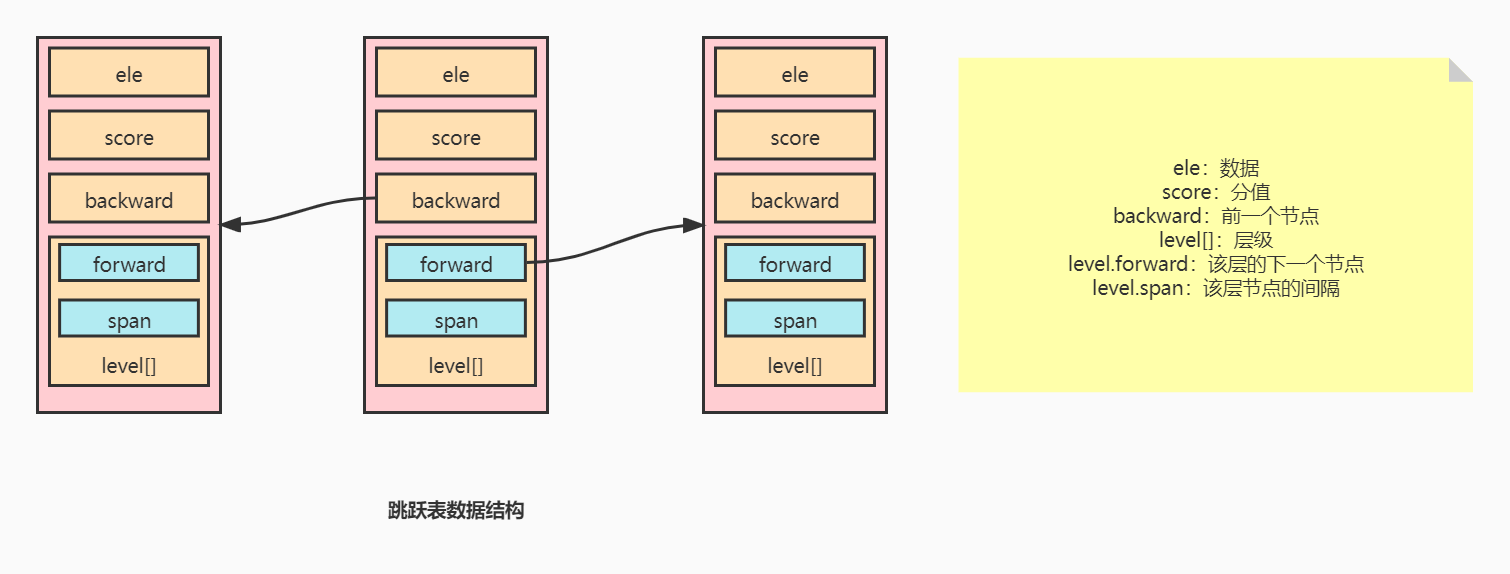
总览
作用于
- 数量比较少的hash、zset
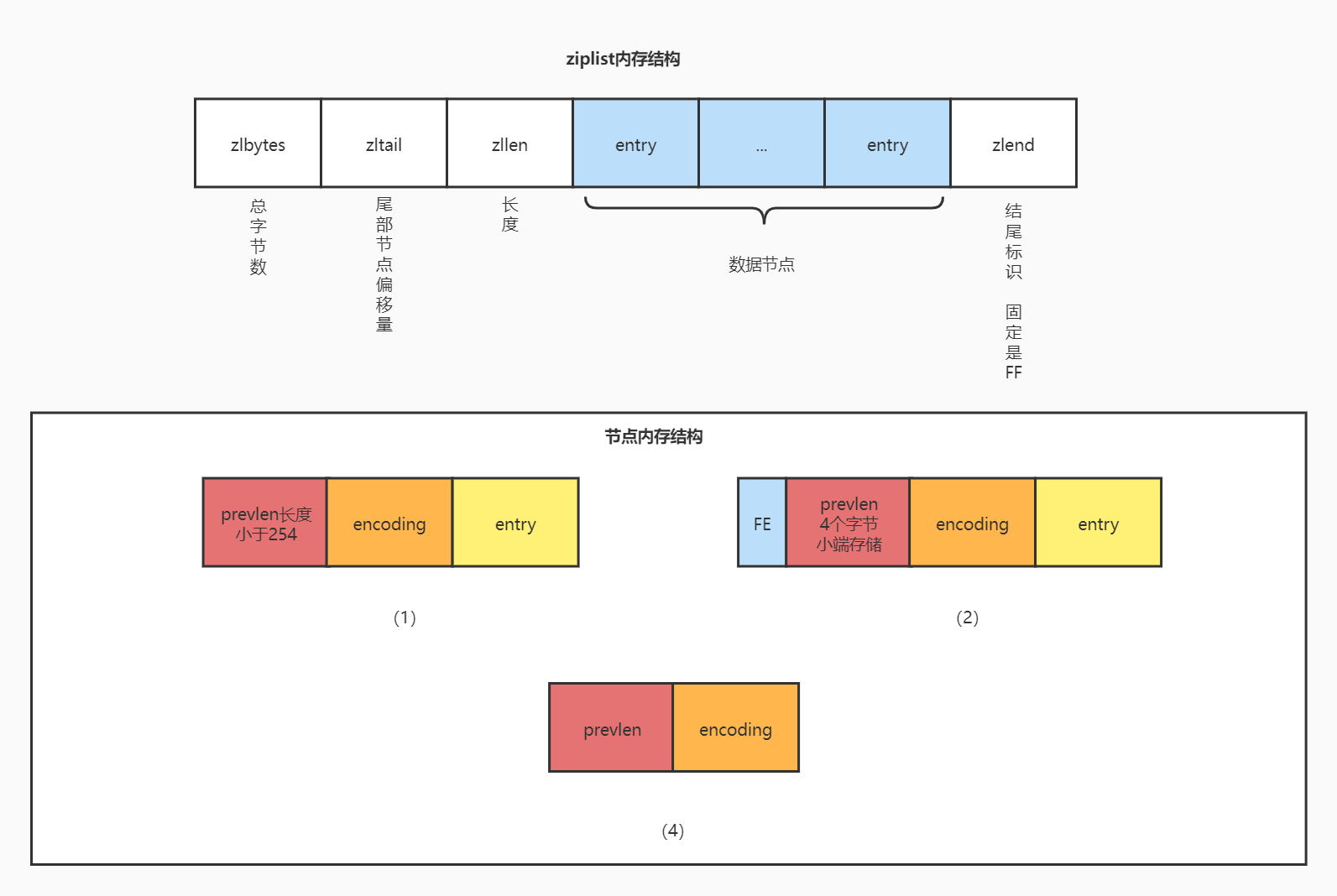
ziplist数据结构
ziplist是一个用一段特殊编码实现的双向链表,优势是占用内存小,可以存储字符串类型和整数类型。在内存布局中包含一下几个字段
- zlbytes:(4 bytes)整个链表占的内存字节数
- zltail:(4 bytes)链表尾部节点的偏移量,存储这个信息的作用是实现反向遍历,因为需要知道尾部的地址才能从尾部向前遍历节点
- zllen:(2 bytes)节点长度
- entry:(n bytes)数据节点,数据节点包含3个结构,下面详细讲解
- zlend:(1 bytes)结束标识符,固定是0xFF
大约 8 分钟